

The line that best fits a data set is the one which minimizes the "distances" between the data points and the fitted line. These are illustrated by the vertical lines in the cartoon below.
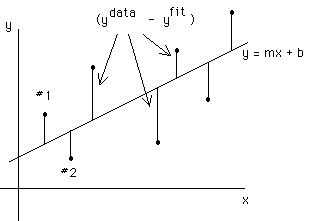
Note that these distances, when defined as ( y data - y fit ), carry a sign + or - depending on whether the data points are above or below the fitted line. To include all the points in a minimization process, the absolute value of these distances must be used; in practice, the square of ( y data - y fit ) is used to avoid mathematical difficulties. So it is customary to define the "standard deviation" as
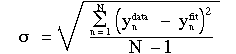
The sum is performed over the N data points. The y fit function is whatever the fitted function maybe, i.e., the straight line fit, evaluated at x n. The denominator (N-1) ":normalizes" the standard deviation such that large and small data sets of comparable goodness of fit have similar values for their standard deviation.
Excel minimizes the standard deviation when it finds the slope and intercept of the straight line which best fits a data set. Therefore, the method is sometimes called "least square fit" or "method of least squares" since it minimizes a "sum of squares".
The standard deviation is a measure of the goodness of the fit for any fit. A smaller number indicates a better fit. Therefore, it provides a quantitative measure by which to compare fits with different functional forms (straight line, power law, or exponential law); the form yielding the smallest standard deviation is the best.
![]() Section 6.4
Section 6.4 ![]() Chapter 6
Chapter 6 ![]() Exercises
Exercises ![]() TOC
TOC
|
Any questions or suggestions should be directed to |