

The aim of mathematical modeling is often to find a relation between a dependent variable "y" and and one or many independent variable(s) "x". We have seen examples of such relations in previous chapters. The question now arises as how should scientists, engineers, financial analysts, ... find guidance in developing such "models". The answer is invariably in the observation of the phenomena to describe. Namely, experiments or observations provide data sets which can be analyzed in terms of "curve fitting", i.e., best suited functional relation to describe the data.
Data sets are often noisy. For example the following is a "fictitious" weight - height data for some small group of male individuals.
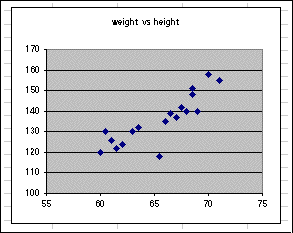
This data is noisy because each person is individual, with his/her own history and ancestry. Other data sets are noisy because of complexity ( value of a stock on the stock market ), statistical nature of a phenomena ( crowd behavior ), measurements inadequacy ( any measurement of physical quantities by engineers or scientists ), ...
The purpose of this chapter is to analyze such noisy data sets, and determine a functional form which best fits the data.
|
Any questions or suggestions should be directed to |